APEX@IGP-FX
10
Metadata
- Introduction
- Types of Metadata
- Harvesting Metadata
- Native XHTML Metadata
- FX Metadata Blocks
- Metadata Identifier
- Processor rules
- Metadata Qualifiers
- FX Metadata Sections
- Metadata Processing
- Remixable Sections
- Provenance and Fixity
- Descriptive Metadata
- Dublin Core as a Definition List
- Other Metadata
- Provenance metadata
- Rights Metadata
- Learning Category Level
- Search Metadata
- Relation Signs
- Metadata Editing in IGP:Digital Publisher
Introduction
Metadata is information about a document rather than document content. The ability to create and maintain significant metadata within a document context for a wide range of purposes is essential for all long-term content ownership strategies.
An FX document is unique in the world of XML type documents in that it has no document type defining outer structure other than the enclosing <galley-rw> element.
An FX package is an assembled collection of ordered sections. In this context it is essential that metadata is used to define the document.
Generally some level of metadata is essential for any content management process to allow core identification and discovery services. We call this Minimum Mandatory Metadata, or M3. That is the metadata that is essential for the content to be usable in a technology solution.
While an FX document is processed complete as a format, the demand for metadata is primarily at the work level. If a document is processed for remixing in a CMS system of some type individual section metadata is generally required.
FX metadata can be added enhanced, extended and processed at any time against content use business drivers.
Metadata is not necessarily static, and an asset may accumulate various types of metadata over time. Metadata may add considerable value to the original document, sections of a document, independent structures within a document, or referencing structures.
Types of Metadata
In the real world there is a wide range of metadata types beyond descriptive metadata. The metadata strategy must be able to handle a wide range of metadata sets, vocabularies and multiple metadata vocabularies each of which may be required for a different presentation or packaging context. Generally metadata is defined from some “standardized” schema's and expressed in XML with a specific DTD and control documents. XML formatted metadata is primarily for machine to machine exchange.
While there are extended and heavily nested metadata schema's, for presentation, forms modification and extraction, filtering, searching and sorting processing, metadata is ideally handled within the XHTML and is available for human review and editing.
It's useful to remember that public controlled schemas are about information exchange. If you are not going to exchange data, public schemes are generally not necessary and can be a significant cost overhead. Where they are required as part of the content ownership business look for the lowest cost method to create and maintain the metadata; then process to the interchange format on demand. You will save a fortune in both metadata generation and maintenance.
FX falls back onto XHTML as the transparent tool which is not a variation on a theme. All metadata schemes use a key-value pair approach with modifications.
The problems start when metadata has to be “nested” to express classification schemes and similar. This is easily addressed with flexibile standardized tagging patterns and relationships such as those defined in thesauruses, taxonomies and other controlled vocabularies.
Harvesting Metadata
Metadata must be able to be harvested and used independently for multiple purposes from the core FX document at any time. A metadata harvesting process can work easily with FX stored metadata for indexing, presentation, conversion or transformation.
For these reasons the metadata associated with a document is created and contained in one or more separate files. This can be maintained with, or inside the primary content file. We recommend that the metadata file is maintained externally to allow it to be enhanced and modified as required without impacting the core content file, and to make it easily accessible for various additional processing such as harvesting cataloguing and reporting data.
Native XHTML Metadata
XHTML itself contains a number of mechanisms for metadata in the XHTML file. All of these can be used in FX, and where appropriate should be used. For example when processing an FX document to a Static webite, SEO Metadata can be inserted into the HTML page head.
Unlike generic XML XHTML defines a <head> element. This contains a number of specific elements and attributes that are very useful for long-term document control. The <head> element is optional in XHTML, but its presence is mandatory in FX. It is the responsibility of creating agents to ensure the <head> element is included and correctly formed.
Note that the metadata values used in the <head> element are controlled and limited for a valid XHTML file.
While FX is always XHTML, it does allow various packaging methods to be used. It could be a single file, it could be multiple files. Therefore relying on the XHTML <head> element is not a long term content management strategy.
FX Metadata Blocks
To allow metadata to be defined and used in almost any postion within a document FX uses a metadata <div> container. This includes a <pre> element in which the metadata is created. This has the advantage that no XHTML validation parser will recognize the content as metadata, and that it can be easily presented in an interface for editing.
The pattern follows the HTML <meta name=" " value=" " /> because there is no reason to invent another vocabulary for this tagging pattern.
<div class="metadata-rw metadata-qualifier-rw"> <pre> <meta name="*" content="*" /> <meta name="*" content="*" /> <meta name="*" content="*" /> </pre> </div>
Metadata can be extended and customized in any manner as long as a processor is available that can use the patterns.
FX does have metadata which is processing instructions and uses custom patterns. This is for specific formats and processing jobs such as file-renaming, search indexing, and other processes.
Metadata Identifier
The selector metadata-rw is applied to all metadata blocks and sections as the first selector always.
A metadata qualifier must always start with the word metadata. IE. The pattern is always metadata-qualifier-rw.
Metadata container qualifiers are part of the controlled FX vocabulary
Processor rules
For this tagging pattern the processor rules are:
- Metadata will always be in a structural <div> container.
- There will only be one qualified type of metadata in a metadata container. IE the qualifier constrains the metadata for a single purpose.
- Metadata terms are always be in a <pre> element
- metadata is always store as a name, value pair.
- A processor must explicitly know how to process metadata by name item.
Metadata Qualifiers
FX defines the following standard metadata qualifiers, which can be arbitrarily expanded at any time.
metadata-work-rw Metadata placed on the title page
metadata-section-rw Metadata placed as the first or last child in a section provides metadata about a section. There may be multiple metadata blocks in a section
metadata-heading-rw Metadata placed as the first child after a heading provides information about the document sub-division until the next heading.
metadata-block-rw Metadata placed inside a text, image or table block that provides information about the content in that block.
metadata-search-rw Used for search optimized metadata such as facets and keywords
seo-metadata-rw Used for standard SEO metadata for static site creation. This has a non-standard construction for historical reasons.
igp-metadata-rw Used for processing instructions for static site creation. This has a non-standard construction for historical reasons.
FX Metadata Sections
FX supports complete metadata sections in addition to block metadata. Section metadata applies to the whole document and is placed at the beginning of a document and before cover or any frontmatter. They are always excluded in an format generation.
A Metadata section is in title case like all FX named sections. Metadata sections are used to provide metadata for the work and can have block metadata processed in from content sections if tagging is at a stage where IDs are applied and static. However this is not recommended except as a separate generated component that is processed for system interchange.
Metadata sections always show the design profile to which they apply with the dp-****-rw reserved pattern. The selector dp-Default-rw is defined as the global metadata container unless other design profiles exist.
<div class="metadata-rw MetadataWork-rw dp-Default-rw" <pre> .... </pre> </div>
Multiple sections can be used for metadata variations for multiple Design Profiles. For example:
<div class="metadata-rw MetadataWork-rw dp-HardCover-rw" <pre> .... </pre> </div>
This defines a metadata section page that applies only to the HardCover design profile using the FX Design Profile "exclusive include" rule.
Metadata Processing
Remixable Sections
When a document is split into separate sections for any reason (Eg: Advanced Content Objects - ACOs), work metadata must be processed into all extracted sections. This provides downstream applications and processors the ability to to understand the section relationship to its parent work.
When files are processed for separate use the relations metadata must always be included. Eg: The Work is represented by the MetadataWork-rw section and the frontmatter sections.
Provenance and Fixity
It must be possible for a search indexing application or generic processor to correctly extract and use metadata for business operations such as discovery and search, rights management, provenance verification, file fixity information. Provenance and fixity metadata can be generated by the FX archive packaging software. All other metadata must be provided by the content owner.
Descriptive Metadata
Dublin Core as a Definition List
The following example fragment shows simple key-value metadata expression. Metadata is expressed as Definition lists because of their ease of automated modification, presentation power with CSS, and because they are easy to extend with additional information. Definition lists also allow the inclusion of other list types, which can be useful where there are a lists of similar metadata terms.
This pattern matches the DC term list with simple term/definition pairs. Note it does not try to provide extended descriptors. The following example uses basic DC Terms and is extended with an no-DC keywords item.
<div class="metadata-rw MetadataWork-rw dp-Default-rw"
<pre>
<meta content="DC.title" value="Work Title" />
<meta content="DC.creator" value="Author Name" />
<meta content="DC.subject" value="Subject text or code" />
<meta content="DC.description" value="Descriptive text" />
<meta content="DC.publisher" value="Publisher Name" />
<meta content="DC.contributor" value="Author Name" />
<meta content="DC.date" value="Date" />
<meta content="DC.type" value="Type statement" />
<meta content="DC.format" value="Format description" />
<meta content="DC.publisher" value="Publisher Name" />
<meta content="DC.identifier" value="ISBN or similar" />
<meta content="DC.source" value="Source Statement" />
<meta content="DC.language" value="en language code" />
<meta content="DC.relation" value="relation" />
<meta content="DC.coverage" value="Coverage statement" />
<meta content="DC.rights" value="Rights statement" />
<meta content="keywords" value="text, text, text" />
</pre>
</div>
In this example the DC. pseudo namespace does not mean anything unless a processor has the ability to understand it.
Other Metadata
There is a requirement for other informational and administration metadata types beyond descriptive. By default FX has metadata blocks for:
Provenance Automatically generated in the FX Package if the file is produced using IGP:Digital Publisher.
Rights Rights can be inserted at the work, section or block level. Internally IGP uses a custom variant of the ODRL grammar to address use and reuse rights.
Fixity File information - generated in FX packaging, stored separately as the manifest file.
Learning (SCORM) Learning category level is available.
Statistics IGP:Digital Publisher can create and store word, character and block statistics for any work or section. This can be regarded as part of, or an extension of fixity metadata. This is particularly useful in evaluating content for reuse.
Search Metadata. Creation of multiple facets that can be used by a search engine, search service or application for discovery and retrieval.
Relation Signs for Usage Tracking PRISM style relations metadata can be included for tracking of part, translation and derivatives by other agents.
Provenance metadata
It is important with future value encoded content to understand how the XML was produced. This allows future verification of subjective and objective structures by agent and organization. It is essential for long-term digital archiving.
The following meta name values are optional, but if used must be these terms with this capitalization.
FX.Producer. The tool or technology environment that was used to create the FX.
FX.Producer Version. Tools change capabilities (and bugs) over time. Therefore it is important to have a version reference.
FX.Producer License ID. For completeness. Digital archive quality content should not be produced using pirated software. If it is Open Source this should be stated.
FX.Output Generator. If the FX was produced by a conforming processor or QC technology, this should be stated.
FX.Applied. Which version of IGP:FoundationXHTML was applied. If it contains custom classes, this should be stated.
FX.Generated Date/Time. The exact local, date and time the file was formed.
FX.Producer Organization. The name of the organization, and preferrably the business sub-unit.
<div class="metadata-rw metadata-provenance-rw"> <pre> <meta name="FX.Producer-App" content="IGP:Digital Publisher" /> <meta name="FX.Producer Version" content="1.5.4 /> <meta name="FX.Producer License ID" content="AZA037" /> <meta name="FX.Output Generator" content="IGP:Formats on Demand 1.0" /> <meta name="FX.Applied" content="IGP:FoundationXHTML" /> <meta name="FX.Template" content="DP-Master-2012-3" /> <meta name="FX.Generated Date/Time" content="2009-12-17 14:21:38 IST" /> <meta name="FX.Producer-Org" content="Infogrid Pacific, Pune, India" /> </pre> </div>
Rights Metadata
Rights metadata is not well defined in an vocabularies. FX uses a variant of the ODRL (Open Digital Rights Language) to express the concept of an offer and agreement between two parties.
<div class="metadata-rw metadata-rights-rw"> <pre> <meta name="offer" content="http://images.infogridpacific.com" /> <meta name="agreement" content="transaction:ar/5567/0098" /> <meta name="permission" content="use once" /> <meta name="rights" content="use" /> <meta name="constraints" content="print only" /> <meta name="agent" content="copyright holder" /> <meta name="usage" content="with permission" /> </pre> </div>
Learning Category Level
The default learning category metadata used by Infogrid Pacific is usually standard SCORM metadata. There are other extensive vocabularies for different analysis. There is usually a need by education publishers for their own controlled vocabularies.
<div class="metadata-rw metadata-learning-category-rw"> <pre> <meta name="context" content="training" /> <meta name="difficulty" content="medium" /> <meta name="intendedEndUserRole" content="student" /> <meta name="interactivityLevel" content="low" /> <meta name="interactivityType" content="expositive" /> <meta name="learningResourceType" content="narrative text" /> <meta name="semanticDensity" content="medium" /> </pre> </div>
Search Metadata
Search metadata for faceted search can be created against a specific requirement for an application. This is a highly custom project level metadata set and will generally have a custom qualifier.
This example is one that was specifically created for the retrieval and purchase of past exam papers at a university.
<div class="metadata-rw metadata-search-rw"> <pre> <meta name="taxonomy" content="Defined taxonomy" /> <meta name="Faculty" content="Science" /> <meta name="Department" content="Geology" /> <meta name="Course" content="Seismic Methods" /> <meta name="Year" content="2003" /> <meta name="Semester" content="Semester 1." /> </pre> </div>
Relation Signs
Relation signs allow extensive mapping of the usage of content objects. An FX document will normally have a simple isPartOf relationship with the Work Metadata. This metadata will generally be used managed by an external application such as IGP:Editorial Content Fulfilment with TUCO (Tracking Usage of Content Objects). This is only provided as an example.
Typically the metadata-work section will have a list of hasParts items referencing the DP system key value, and each section will have a isPartof reference to the Work Identifier.
<div class="metadata-rw metadata-relations-rw"> <pre> <meta name="isPartOf" content="meta-Work reference" /> <meta name="hasPart" content="Content Object Reference" /> <meta name="isUsedBy" content="meta-Work reference" /> <meta name="Uses" content="Content Object Reference" /> <meta name="isDerivativeOf" content="meta-Work reference" /> <meta name="hasDerivative" content="Content Object Reference" /> <meta name="isTranslationOf" content="medium" /> <meta name="hasTranslation" content="Content Object Reference" /> </pre> </div>
Metadata Editing in IGP:Digital Publisher
An advantage of the structure of the metadata block is that it can be both processed into a document and hand edited where-ever it appears.
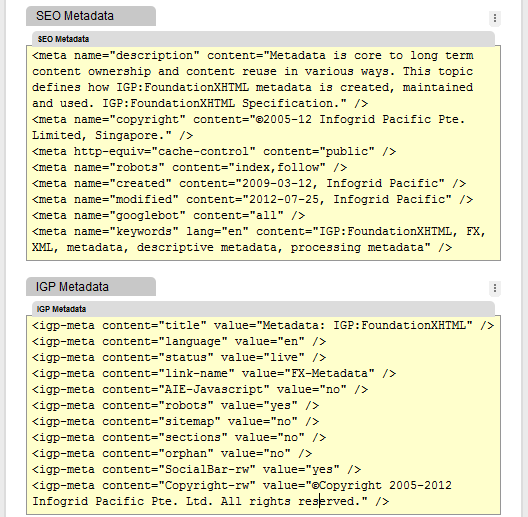
This screengrab from IGP:Writer shows the SEO metadata and IGP Metadata blocks inserted in this actual page. In this case the metadata is used by the StaticSite processor as the pages are converted to discoverable webpages. SEO-Metadata is inserted into the generated HTML5 page, IGP-Metadata is a set of processing instructions for the Formats on Demand packaging processors.
Extraction of Metadata from tagged content
FX does not recommend extraction of metadata from tagged content. Our experience over thousands of documents is that content tagged metadata will not be reliable or consistent in the long term, even if high quality tagging strategies are used.
While tagging of core metadata in content is allowed, for real use metadata should always be constructed in such a way that it can be independently verified and use. For this reason IGP:FoundationXHTML supports a powerful set of metadata tools and options.